
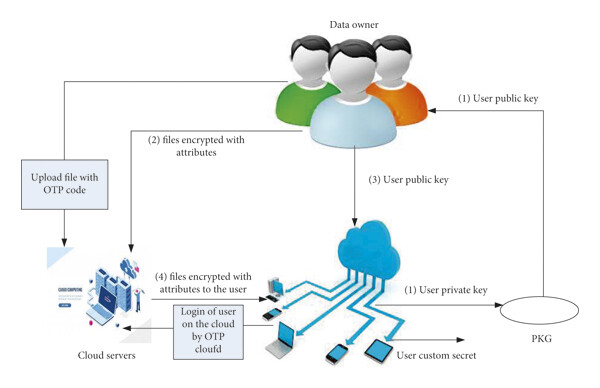
A New Secure Model for Data Protection over Cloud Computing
The main goal of any data storage model on the cloud is accessing data in an easy way without risking its security. A security consideration is a major aspect in any cloud data storage model to provide safety and efficiency. In this paper, we propose a secure data protection model over the cloud. The proposed model presents a solution to some security issues of cloud such as data protection from any violations and protection from a fake authorized identity user, which adversely affects the security of the cloud. This paper includes multiple issues and challenges with cloud computing that

Specialized Syntactic Quran Search Engines: Evaluation and Limitations
The Quran is the sacred text that provides guidance and teachings to the followers of Islam. This paper aims to analyze and evaluate the limitations of current specialized search engines used for retrieving information from the Quran. Also, this work includes an initial evaluation of Quran search with a large language model (LLM) employing prompt engineering. The study focuses on the syntactic aspect of information retrieval, while acknowledging the necessity of considering the semantic meaning of Quranic words and verses for a more comprehensive analysis. Furthermore, recommendations and
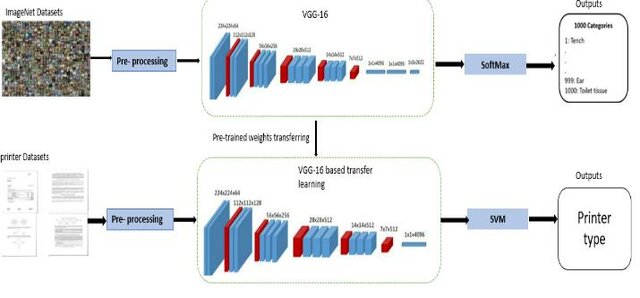
An Efficient Source Printer Identification Model using Convolution Neural Network (SPI-CNN)
Document forgery detection is becoming increasingly important in the current era, as forgery techniques are available to even inexperienced users. Source printer identification is a method for identifying the source printer and classifying the questioned document into one of the printer classes. According to what we know, most earlier studies segmented documents into characters, words, and patches or cropped them to obtain large datasets. In contrast, in this paper, we worked with the document as a whole and a small dataset. This paper uses three techniques dependent on CNN to find the
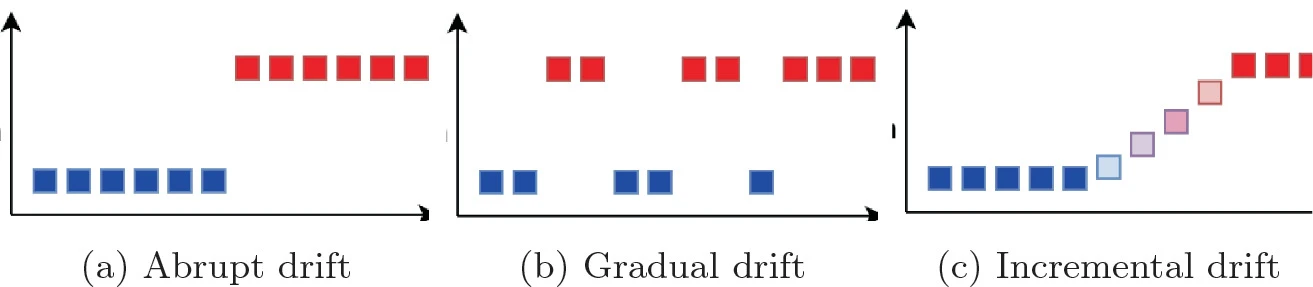
Benchmarking Concept Drift Detectors for Online Machine Learning
Concept drift detection is an essential step to maintain the accuracy of online machine learning. The main task is to detect changes in data distribution that might cause changes in the decision boundaries for a classification algorithm. Upon drift detection, the classification algorithm may reset its model or concurrently grow a new learning model. Over the past fifteen years, several drift detection methods have been proposed. Most of these methods have been implemented within the Massive Online Analysis (MOA). Moreover, a couple of studies have compared the drift detectors. However, such

Sentiment-Based Spatiotemporal Prediction Framework for Pandemic Outbreaks Awareness Using Social Networks Data Classification
According to the World Health Organization, several factors have affected the accurate reporting of SARS-CoV-2 outbreak status, such as limited data collection resources, cultural and educational diversity, and inconsistent outbreak reporting from different sectors. Driven by this challenging situation, this study investigates the potential expediency of using social network data to develop reliable early information surveillance and warning system for pandemic outbreaks. As such, an enhanced framework of three inherently interlinked subsystems is proposed. The first subsystem includes data
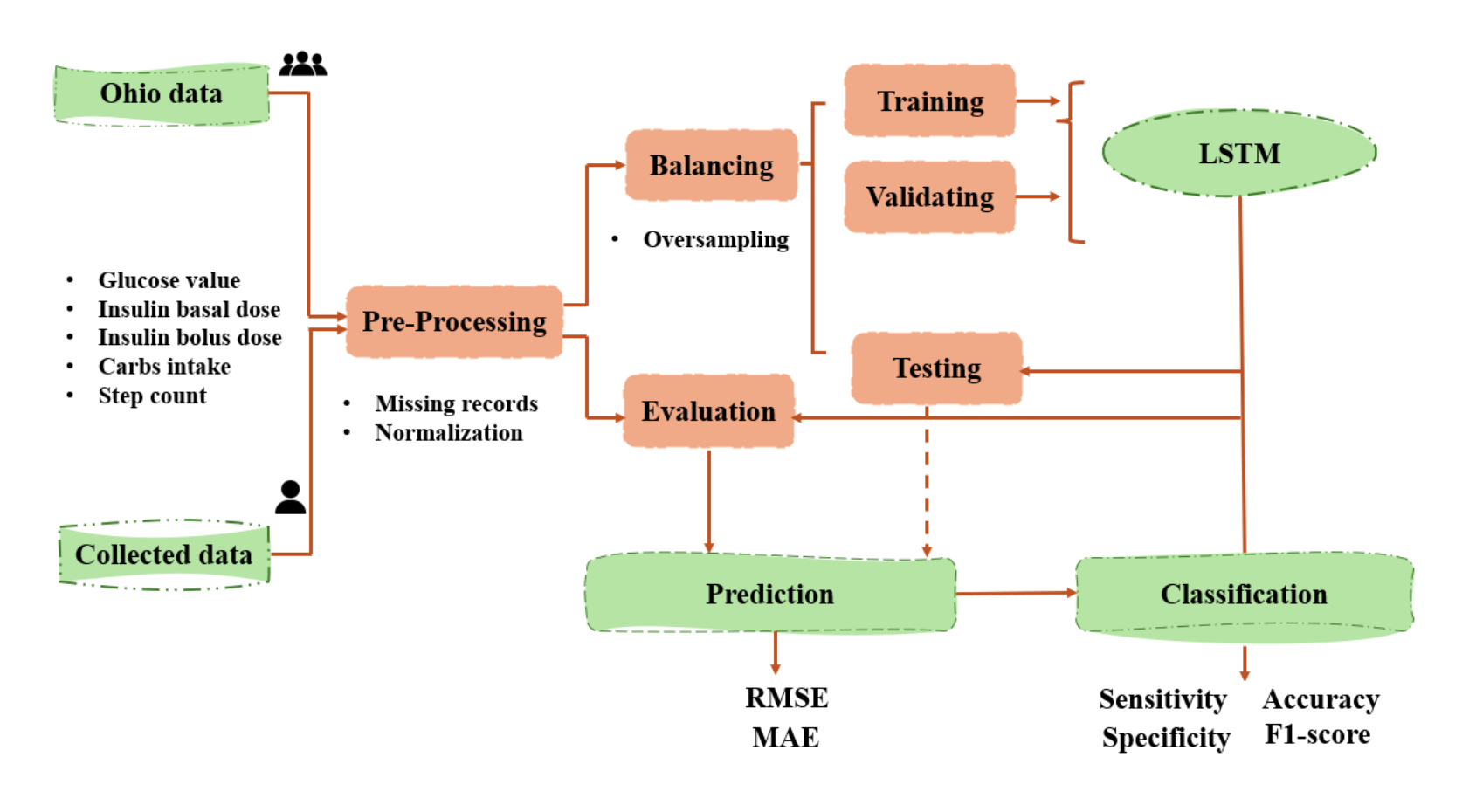
Intelligent Real-Time Hypoglycemia Prediction for Type 1 Diabetes
Hypoglycemia in Type 1 Diabetes (T1D) refers to a condition where blood glucose (BG) levels drop to abnormally low levels, typically below 70 mg/dL. This can occur when there is an excessive amount of insulin relative to the blood glucose level, leading to an imbalance that can be dangerous and potentially life-threatening if not promptly treated. The availability of large amounts of data from continuous glucose monitoring (CGM), insulin doses, carbohydrate intake, and additional vital signs, together with deep learning (DL) techniques, has revolutionized algorithmic approaches for BG

Automated Deep Learning Pipeline for Accurate Segmentation of Aortic Lumen and Branches in Abdominal Aortic Aneurysm: A Two-Step Approach
Abdominal Aortic Aneurysm (AAA) is a serious medical condition characterized by the abnormal enlargement of the abdominal aorta. If left untreated, AAA can have life-threatening consequences. Accurate segmentation of the aorta in Computed Tomography Angiography (CTA) images plays a vital role in treatment planning for AAA. However, manual and semi-automatic segmentation methods suffer from limitations in terms of time and accuracy. This study presents a deep learning pipeline that aims to fully automate the precise and efficient segmentation of the aorta and its branches within CTA images. A
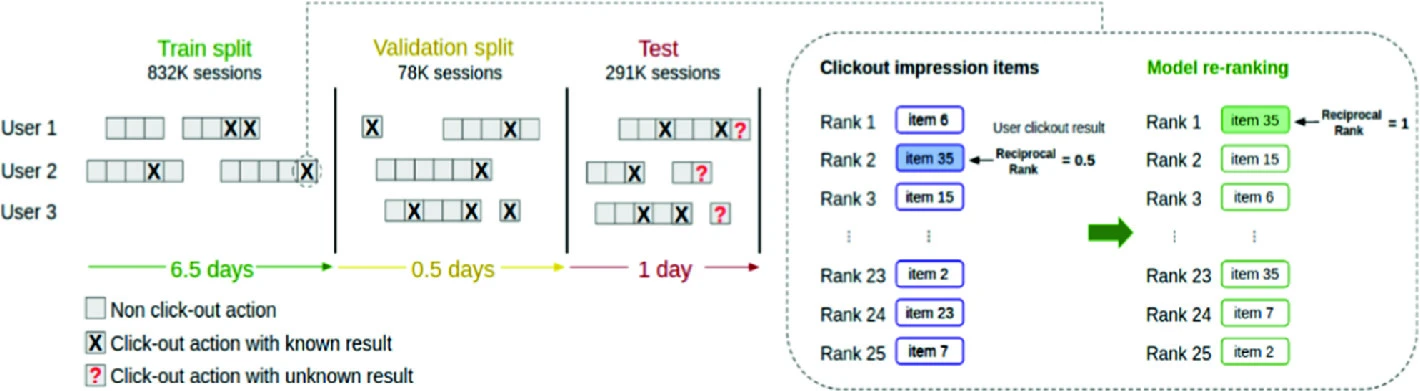
Recommendations on Streaming Data: E-Tourism Event Stream Processing Recommender System
The Association for Computing Machinery ACM recommendation systems challenge (ACM RecSys) [1] released an e-tourism dataset for the first time in 2019. Challenge shared hotel booking sessions from trivago website asking to rank the hotels list for the users. Better ranking should achieve higher click out rate. In this context, Trivago dataset is very important for e-tourism recommendation systems domain research and industry as well. In this paper, description for dataset characteristics and proposal for a session-based recommender system in addition to a comparison of several baseline
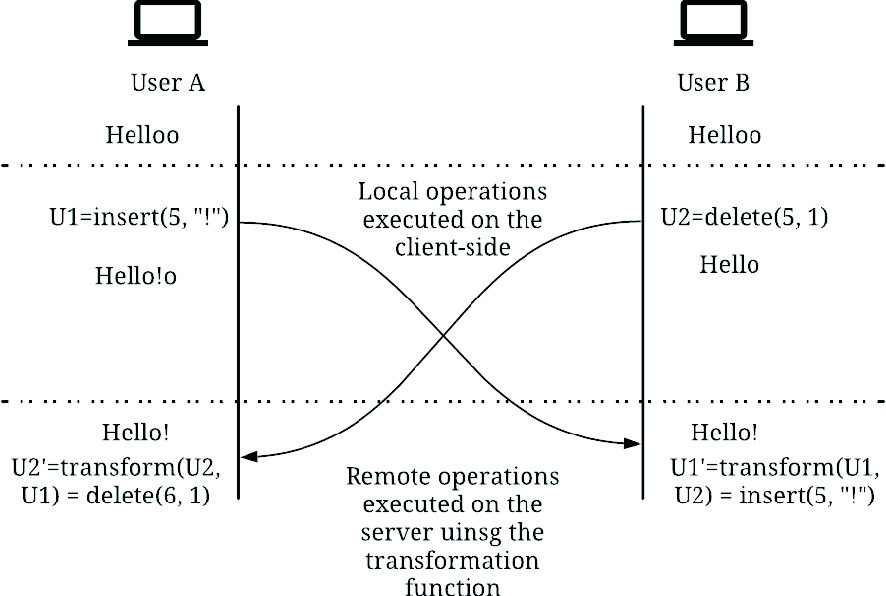
A Survey of Concurrency Control Algorithms in Collaborative Applications
Collaborative applications are becoming more prevalent for a variety of reasons, most important of which is the increased interest in remote work. In addition to adapting the business processes to a remote setting, designers of collaborative software have to decide on how their software can be used collaboratively. This paper discusses the two main technologies used to enable network-based real- or near-real-time collaborative software, namely Operational Transformation and Conflict-free Replicated Data Types. Recent developments in each technology are discussed, as well as a brief overview of
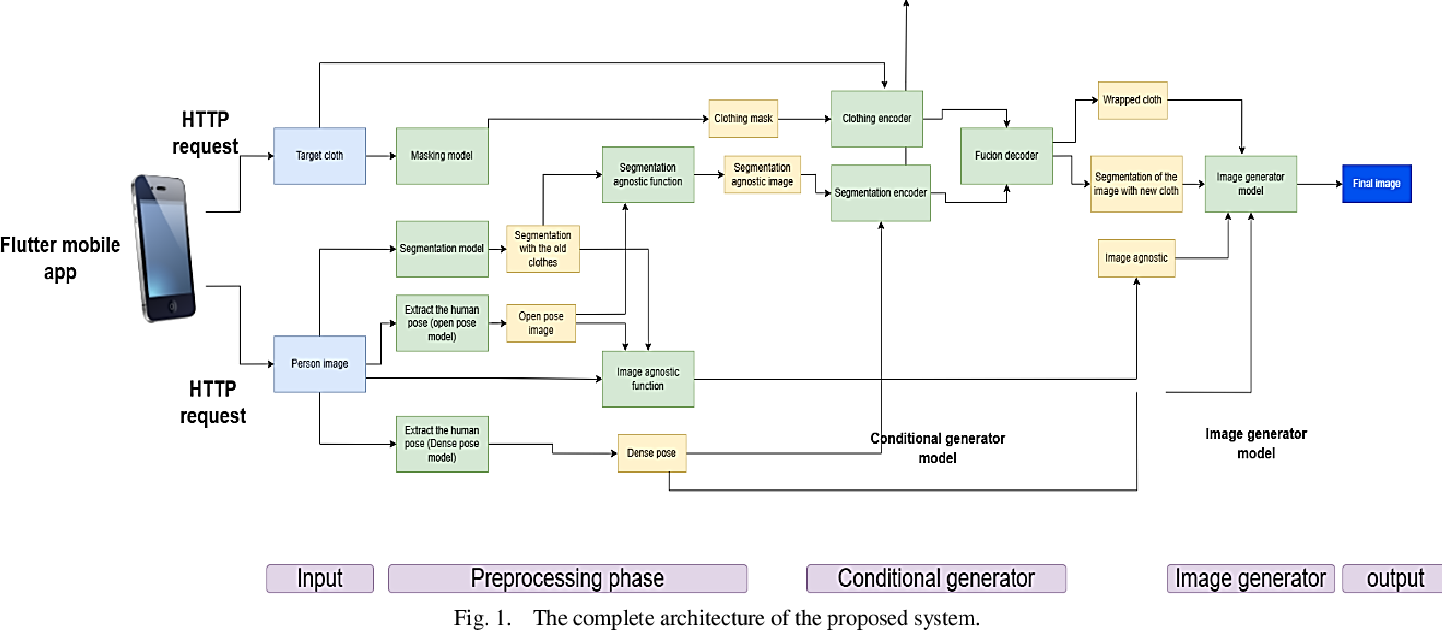
A Cost-Efficient Approach for Creating Virtual Fitting Room using Generative Adversarial Networks (GANs)
Customers all over the world want to see how the clothes fit them or not before purchasing. Therefore, customers by nature prefer brick-and-mortar clothes shopping so they can try on products before purchasing them. But after the Pandemic of COVID19 many sellers either shifted to online shopping or closed their fitting rooms which made the shopping process hesitant and doubtful. The fact that the clothes may not be suitable for their buyers after purchase led us to think about using new AI technologies to create an online platform or a virtual fitting room (VFR) in the form of a mobile