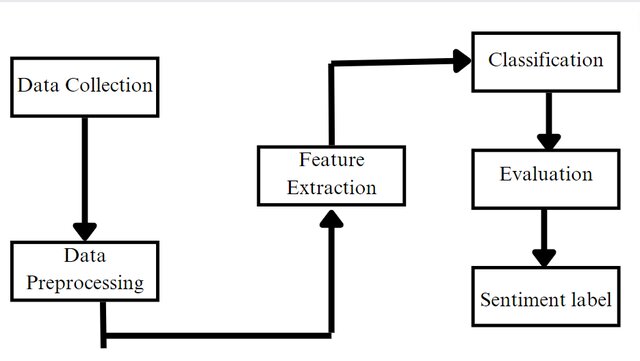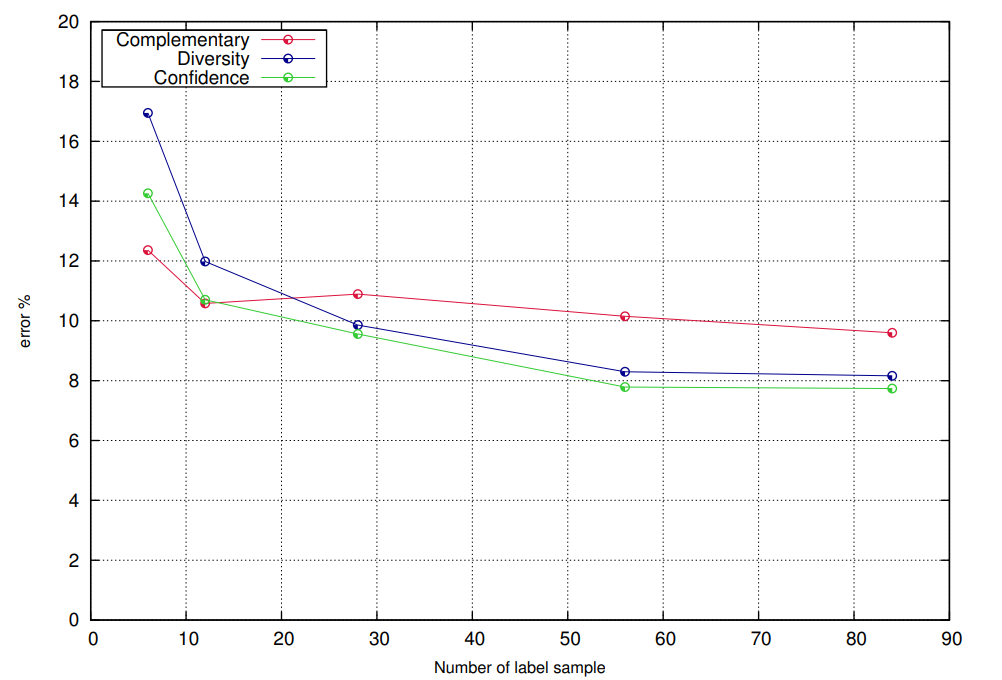
Complementary feature splits for co-training
In many data mining and machine learning applications, data may be easy to collect. However, labeling the data is often expensive, time consuming or difficult. Such applications give rise to semi-supervised learning techniques that combine the use of labelled and unlabelled data. Co-training is a popular semi-supervised learning algorithm that depends on splitting the features of a data set into two redundant and independent views. In many cases however such sets of features are not naturally present in the data or are unknown. In this paper we test feature splitting methods based on maximizing the confidence and the diversity of the views using genetic algorithms, and compare their performance against random splits. We also propose a new criterion that maximizes the complementary nature of the views. Experimental results on six different data sets show that our optimized splits enhance the performance of co-training over random splits and that the complementary split outperforms the confidence, diversity and random splits. © 2012 IEEE.